经过近一个月时间,终于差不多将之前在Flume 0.9.4上面编写的source、sink等插件迁移到Flume-ng 1.5.0,包括了将Flume 0.9.4上面的TailSource、TailDirSource等插件的迁移(当然,我们加入了许多新的功能,比如故障恢复、日志的断点续传、按块发送日志以及每个一定的时间轮询发送日志而不是等一个日志发送完才发送另外一个日志)。现在 w397090770 11年前 (2014-06-18) 17534℃ 13评论15喜欢
本文将介绍使用Spark batch作业处理存储于Hive中Twitter数据的一些实用技巧。首先我们需要引入一些依赖包,参考如下:[code lang="scala"]name := "Sentiment"version := "1.0"scalaVersion := "2.10.6"assemblyJarName in assembly := "sentiment.jar"libraryDependencies += "org.apache.spark" % "spark-core_2.10" % "1.6.0&qu zz~~ 8年前 (2016-08-31) 3337℃ 0评论5喜欢
Spark Release 1.0.2于2014年8月5日发布,Spark 1.0.2 is a maintenance release with bug fixes. This release is based on the branch-1.0 maintenance branch of Spark. We recommend all 1.0.x users to upgrade to this stable release. Contributions to this release came from 30 developers.如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopYou can download Spark 1.0.2 as w397090770 10年前 (2014-08-06) 5823℃ 2评论4喜欢
Linux安装软件依赖问题解决办法[code lang="java"][wyp@localhost Downloads]$ rpm -i --aid AdobeReader_chs-8.1.7-1.i486.rpm error: Failed dependencies: libatk-1.0.so.0 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6 is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.0) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1) is needed by AdobeReader_chs-8.1.7-1.i486 libc.so.6(GLIBC_2.1.3) is n w397090770 10年前 (2014-10-09) 7823℃ 0评论4喜欢
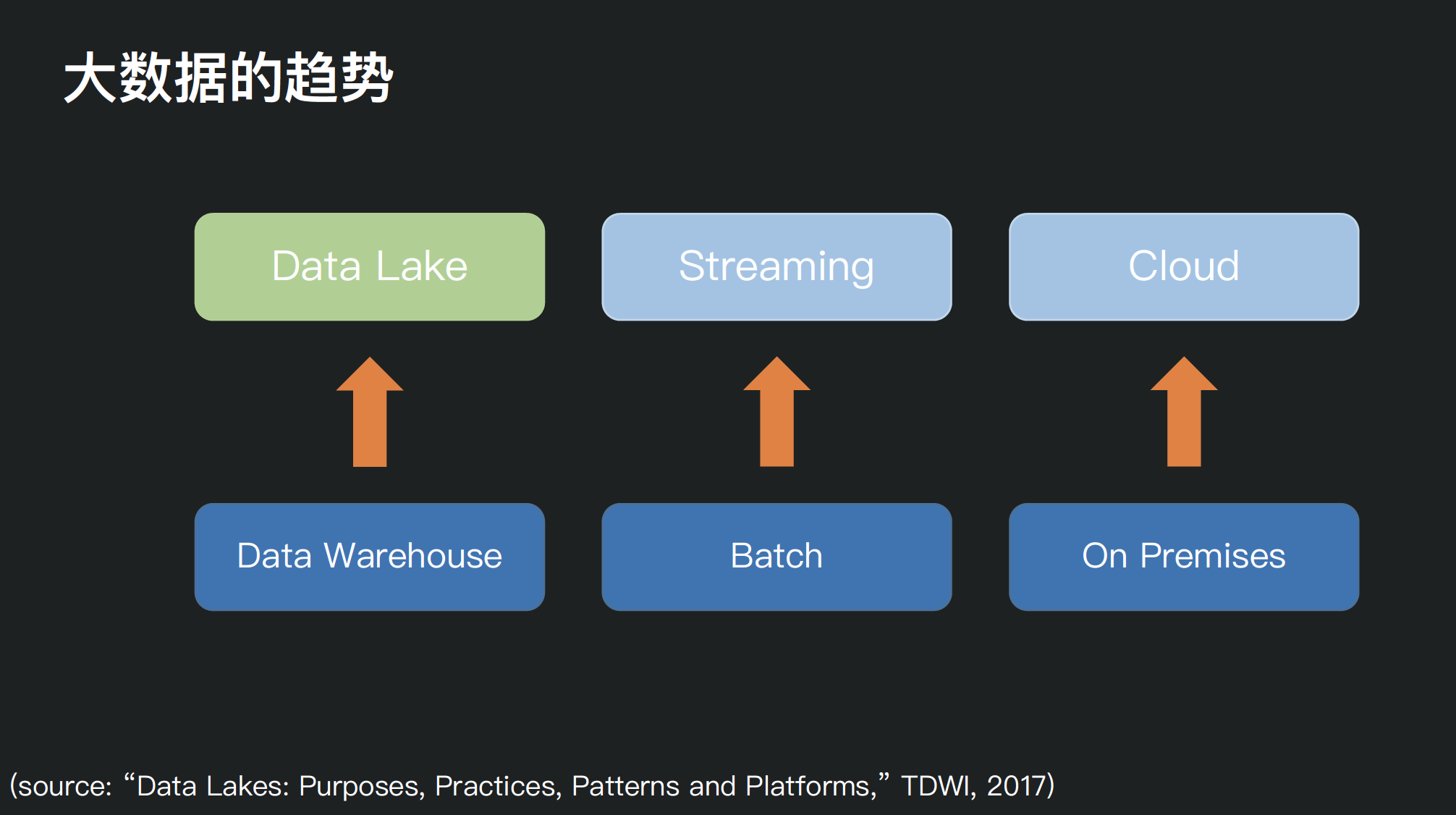
本文资料来自2020年9月5日由快手技术团队主办的快手大数据平台架构技术交流会,分享者邵赛赛,腾讯数据平台部数据湖内核技术负责人,资深大数据工程师,Apache Spark PMC member & committer, Apache Livy PMC member,曾就职于 Hortonworks,Intel 。随着大数据存储和处理需求的多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式 w397090770 4年前 (2020-09-07) 4535℃ 3评论8喜欢
这篇文章本来19年5月份就想写的,最终拖到今天才整理出来😂。Spark 内置给我们带来了非常丰富的各种优化,这些优化基本可以满足我们日常的需求。但是我们知道,现实场景中会有各种各样的需求,总有一些场景在 Spark 得到的执行计划不是最优的,社区的大佬肯定也知道这个问题,所以从 Spark 1.3.0 开始,Spark 为我们提供 w397090770 4年前 (2020-08-05) 1114℃ 2评论3喜欢
2016中国架构师大会大数据专场于10月27日在京进行,大数据专场有来自搜狐、优酷介绍其视频个性化推荐架构设计;也有来自饿了么的实时架构演变;有来自Qunar、宜信以及广发证券再金融中应用大数据的架构设计;也有华为CarbonData的介绍,干货十足!值得一看。主要涉及如下主题: 10月27 w397090770 8年前 (2016-11-03) 4733℃ 0评论9喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1038℃ 0评论1喜欢
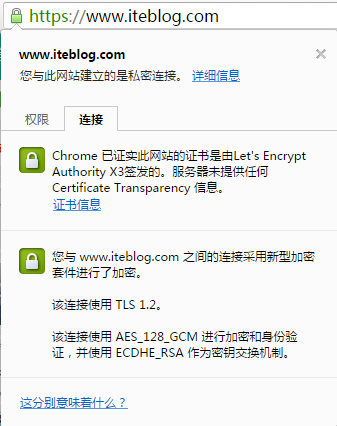
我昨天在《如何申请免费好用的HTTPS证书Let's Encrypt》中详细地介绍了申请免费的Let's Encrypt证书步骤,如果大家按照上面的文章介绍一步一步地操作我们可以在/data/web/ssl/文件夹下看到如下的文件列表:[code lang="bash"][iteblog@iteblog.com ssl] $ lltotal 28-rw-r--r-- 1 iteblog iteblog 3243 Aug 5 09:21 account.key-rw-r--r-- 1 iteblog iteblog 9159 Aug 5 09:33 w397090770 8年前 (2016-08-07) 1994℃ 0评论2喜欢
据估计,到2017年底,90%的CPU cycles 将会致力于移动硬件,移动计算正在迅速上升到主导地位。Spark为此重新设计了Spark体系结构,允许Spark在移动设备上运行Spark。 Spark为现代化数据中心和大数据应用进行设计和优化,但是它目前不适合移动计算。在过去的几个月中,Spark社区正在调研第一个可以在移动设备上运行架构的可 w397090770 10年前 (2015-04-14) 8025℃ 0评论10喜欢
ZooKeeper 支持某些特定的四字命令(The Four Letter Words)与其进行交互。它们大多是查询命令,用来获取 ZooKeeper 服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向 ZooKeeper 提交相应的命令。 ZooKeeper 常用四字命令主要如下: ZooKeeper四字命令功能描述conf3.3.0版本引入的。打印出服务相关配置的详细信息。cons3.3.0 w397090770 9年前 (2016-05-18) 4256℃ 0评论5喜欢
本博客前两篇文章介绍了如何在脚本中使用Scala(《在脚本中运行Scala》、《在脚本中使用Scala的高级特性》),我们可以在脚本里面使用Scala强大的语法,但细心的同学可能会发现每次运行脚本的时候会花上一大部分时间,然后才会有结果。我们来测试下面简单的Scala脚本:[code lang="shell"]#!/bin/shexec scala "$0" "$@" w397090770 9年前 (2015-12-17) 4749℃ 0评论8喜欢
随着网站的文章越来越多,网站的图片也不知不觉的多了起来,图片多起来带来的问题就是访问的人多的时候会导致页面加载速度越来越慢,这严重影响了网站的用户体验,所以网站图片异步加载势在必行。 图片异步加载就是图片只有在视野范围内才加载,没出现在范围内的图片就暂不加载,等用户滑动滚动条时再逐步 w397090770 8年前 (2016-07-08) 3480℃ 0评论7喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5675℃ 0评论14喜欢
PrestoCon Day 2021 在3月24日于在线的形式举办,会议的议程可以参见这里。这里主要是收集了本次会议的 PPT 和视频等资料供大家学习交流使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据下载途径关注微信公众号 过往记忆大数据 或者 Java与大数据架构 并回复 10011 获取。可下载 w397090770 3年前 (2021-07-31) 477℃ 0评论4喜欢
关于如何编译Flume-ng 1.4.0可以参见本博客的《基于Hadoop-2.2.0编译flume-ng 1.4.0及错误解决》 在编译Flume-0.9.4源码的时候出现了以下的错误信息:[code lang="JAVA"][INFO] ------------------------------------------------------------------------[INFO] Reactor Summary:[INFO][INFO] Flume ............................................. SUCCESS [0.003s][INFO] Flume Core ............ w397090770 11年前 (2014-01-22) 10774℃ 2评论2喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16674℃ 1评论6喜欢
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: Flink 与 Hive 集成的 w397090770 4年前 (2020-11-26) 2368℃ 0评论11喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4767℃ 0评论5喜欢
一、先来先服务和短作业(进程)优先调度算法1.先来先服务调度算法先来先服务(FCFS)调度算法是一种最简单的调度算法,该算法既可用于作业调度,也可用于进程调度。当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入 w397090770 12年前 (2013-04-10) 14340℃ 0评论19喜欢
在Spark中内置支持两种系列化格式:(1)、Java serialization;(2)、Kryo serialization。在默认情况下,Spark使用的是Java的ObjectOutputStream系列化框架,它支持所有继承java.io.Serializable的类系列化,虽然Java系列化非常灵活,但是它的性能不佳。然而我们可以使用Kryo 库来系列化,它相比Java serialization系列化高效,速度很快(通常比Java快1 w397090770 10年前 (2015-04-23) 14793℃ 0评论15喜欢
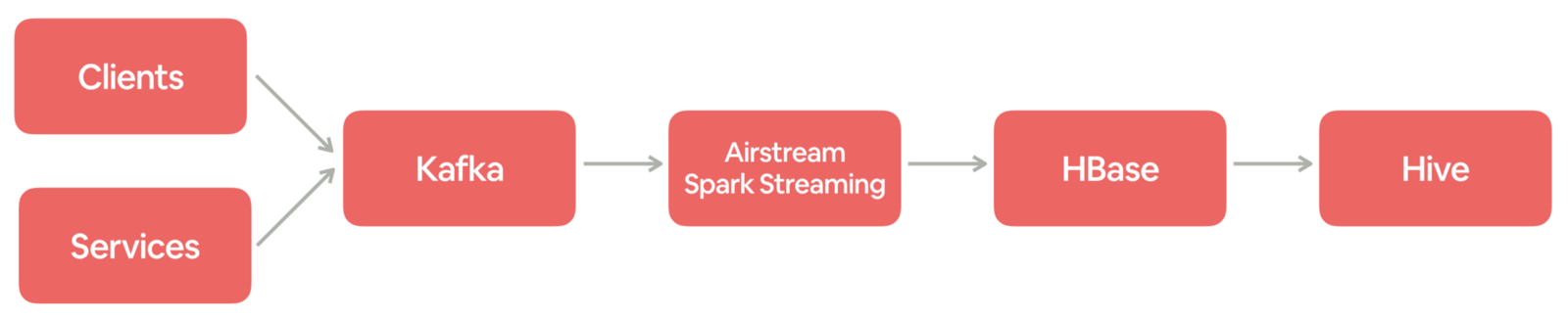
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 6年前 (2019-05-19) 2868℃ 0评论8喜欢
Apache Hive 1.2.0于美国时间2015年05月18日正式发布,其中修复了大量大Bug,完整邮件内容如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopThe Apache Hive team is proud to announce the the release of Apache Hive version 1.2.0.The Apache Hive (TM) data warehouse software facilitates querying and managing large datasets residin w397090770 10年前 (2015-05-19) 5407℃ 0评论4喜欢
北京第十次Spark Meetup活动于北京时间2016年03月27日在北京市海淀区丹棱街5号微软亚太研发集团总部大厦1号楼进行。活动内容如下:1. Spark in TalkingData,阎志涛.TalkingData研发副总裁2. Spark in GrowingIO,田毅,GrowingIO数据平台工程师,主要分享GrowingIO使用Spark进行数据处理过程中的各种小技巧,包括:多数据源的访问和使用Bitmap进行 w397090770 9年前 (2016-03-28) 2125℃ 0评论4喜欢
2019年4月25日,微软的 Rahul Potharaju、Terry Kim 以及 Tyson Condie 在 Spark + AI Summit 2019 会议上为我们带来主题为 《Introducing .NET Bindings for Apache Spark 》的分享,并宣布 .NET for Apache Spark 预览版正式发布。.NET 框架是由微软开发,一个致力于敏捷软件开发、快速应用开发、平台无关性和网络透明化的免费软件框架,用于构建许多不同类型的 w397090770 6年前 (2019-04-28) 15582℃ 0评论4喜欢
Spark已经成为数据科学专业人士最有前途的大数据分析引擎。Apache Spark真正的力量和价值在于它能够以高速和准确的方式执行数据科学任务;Spark的卖点是它结合ETL,批处理分析,实时流分析,机器学习,图形处理和可视化;它允许您轻松处理非结构化的原始数据集。 本书将让您舒适和自信地使用Spark完成数据科学任务。 w397090770 8年前 (2017-02-10) 2233℃ 0评论6喜欢
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数# 查看物理CPU个数cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l# 查看每个物理CPU中core的个数(即核数)cat /proc/cpuinfo| grep "cpu cores"| uniq# 查看逻辑CPU的个数cat /proc/cpuinfo| grep "processor"| wc -l复制代码 查看CPU信息(型号)ca w397090770 3年前 (2021-11-01) 825℃ 0评论3喜欢
谁说网站首次备案一定要关站?特别是网站运行了一段时间,搜索引擎等已经收录了网站内容,这时候如果关站一段时间(备案期间最长需要20个工作日,也就是一个月时间)会对网站产生很大的影响,比如网站被搜索引擎加黑,权重变低。这样的影响我们肯定不想要。 今天我想告诉大家的是其实在备案期间我们网站是可 w397090770 10年前 (2014-12-24) 4375℃ 3评论5喜欢
一个功能健全的kafka集群可以处理相当大的数据量,由于消息系统是很多大型应用的基石,因此broker集群在性能上的缺陷,都会引起整个应用栈的各种问题。Kafka的度量指标主要有以下三类:1.Kafka服务器(Kafka)指标2.生产者指标3.消费者指标另外,由于Kafka的状态靠Zookeeper来维护,对于Zookeeper性能的监控也成为了整个Ka zz~~ 3年前 (2022-05-01) 1347℃ 0评论0喜欢
引言:十年沉淀、全球宽表排名第一、阿里云首发云Cassandra服务ApsaraDB for Cassandra是基于开源Apache Cassandra,融合阿里云数据库DBaaS能力的分布式NoSQL数据库。Cassandra已有10年+的沉淀,基于Amazon DynamoDB的分布式设计和 Google Bigtable 的数据模型。具备诸多优异特性:采用分布式架构、无中心、支持多活、弹性可扩展、高可用、容错、一 w397090770 5年前 (2019-09-05) 2172℃ 0评论4喜欢





![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)




![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)







![[电子书]Apache Spark for Data Science Cookbook PDF下载](https://www.iteblog.com/pic/books/Spark_for_Data_Science_Cookbook_iteblog.jpg)



